통계데이터 인공지능 활용대회 최우수상 후기
in Project on Competition
2022년 5월, 통계청에서 주관한 통계데이터 인공지능 활용대회에 개인으로 참가하여 최우수상(2위)을 수상하였습니다.

대회는 자연어 기반 인공지능 산업분류 자동화를 주제로 진행되었습니다. 특정 산업을 표현하는 20 ~ 30자 길이의 텍스트가 입력되었을 때 230개 산업 중 어떤 산업으로 분류할지 예측하는 텍스트 분류 문제를 다루었고, 100만 개의 학습용 데이터와 10만 개의 검증용 데이터가 주어졌습니다.

당시 부스트캠프 AI Tech를 수료한 후 궁금했지만 시간 부족으로 제대로 공부하지 못하고 넘어간 부분을 채워가고 있었습니다.
부스트캠프 내부에서 진행된 컴페티션 문제를 풀기 위해 숱하게 사용한 허깅페이스 transformers 라이브러리 사용법과 세부 기능을 공부할 수 있는 HuggingFace NLP Course 과정을 쭉 따라가며 정리하였고, 모델링 소스 코드를 살펴보며 라이브러리를 통해 쉽게 불러와서 사용하는 모델이 어떻게 구현되었는지 찾아 보았습니다.
또한, 딥러닝 이론을 좀더 자세히 알고 싶었기 때문에 딥러닝을 위한 수학(아카이시 마사노리), 밑바닥부터 시작하는 딥러닝 1,2(사이토 고키)를 공부하였습니다. 이러한 공부를 통해 피상적으로 이해하고 있던 역전파 과정이 pytorch 같은 딥러닝 프레임워크에서 어떻게 구현되어 있는지 알 수 있게 되었습니다.
그러던 중 대회 포스터를 보았습니다. 그동안 공부한 것들을 활용하여 텍스트 분류 문제를 혼자서 해결할 수 있음을 보이기에 좋겠다고 판단했고, 대회 1위를 목표로 참가하였습니다.
대회 전략
활용할 수 있는 GPU 서버가 없었기 때문에 Colab Pro 환경에서 1개의 GPU를 가지고 문제를 풀어야 했습니다. 뿐만 아니라 대회는 4주간 진행되었으나, 뒤늦게 소식을 듣고 참가하여 저에게 주어진 시간은 3주였습니다.
상대적으로 짧은 시간을 알차게 사용해야 했습니다. 그러므로 대회 기간 동안 최대한 많은 시간을 투자하여 효과가 있을 것으로 기대되는 방법들을 빠르게 시도하고, 효과를 보인 방법들을 조합하여 대회의 평가지표인 Accuracy를 최대화하고자 하였습니다.
대회 기간 동안 하루 평균 15시간 이상은 대회 문제를 풀기 위해 몰입했습니다.
성능 향상을 위한 시도들
1. 이전 계층을 예측하는 모델 결과를 참고하여 예측
대회에서 분류해야 하는 산업은 계층적 구조로 이루어져 있었습니다. 산업 레이블은 큰 카테고리로 19개, 큰 카테고리를 세분화한 중간 카테고리 75개, 중간 카테고리를 더 세분화한 작은 카테고리 230개로 구성됩니다.
그렇기 때문에 큰 카테고리 분류 모델, 중간 카테고리 분류 모델, 작은 카테고리 분류 모델을 각각 따로 학습시키고, 상대적으로 큰 카테고리를 분류하는 모델이 판단한 정보를 작은 카테고리를 분류하는 모델이 참고하여 예측하게 한다면 Accuracy 향상에 도움이 될 것이라고 판단했습니다.
만약 성능이 향상되지 않더라도 이전 계층 정보를 참고하지 않는 모델과 결과가 달라질 것이므로 앙상블 시 더 나은 결과를 만들어 낼 수 있을 것이라고 기대하고 시도하였습니다.
- 관련 코드 발췌, 허깅페이스 모델링 코드 활용
checkpoint = { "previous": f"{cfg.model}/second/checkpoint-56248", "present": f"{cfg.model}/Negative_Sampling/2/checkpoint-62232", } config = AutoConfig.from_pretrained(checkpoint["present"], num_labels=225) class AddSecondModel(RobertaForSequenceClassification): def __init__(self, config, checkpoint): super().__init__(config) self.num_labels = config.num_labels self.config = config # 대분류 모델 불러오기 self.model_first = RobertaModel.from_pretrained( checkpoint["previous"], add_pooling_layer=False ) # 대분류 모델 프리징 for param in self.model_first.parameters(): param.requires_grad_(False) self.model = RobertaModel.from_pretrained( checkpoint["present"], config=config, add_pooling_layer=False ) self.norm = nn.LayerNorm(config.hidden_size) self.classifier = RobertaClassificationHead(config) # self.init_weights() def forward( self, input_ids=None, attention_mask=None, token_type_ids=None, position_ids=None, head_mask=None, inputs_embeds=None, labels=None, output_attentions=None, output_hidden_states=None, return_dict=None, ): r""" labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size,)`, `optional`): Labels for computing the sequence classification/regression loss. Indices should be in :obj:`[0, ..., config.num_labels - 1]`. If :obj:`config.num_labels == 1` a regression loss is computed (Mean-Square loss), If :obj:`config.num_labels > 1` a classification loss is computed (Cross-Entropy). """ return_dict = return_dict if return_dict is not None else self.config.use_return_dict first_outputs = self.model_first( input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids, position_ids=position_ids, head_mask=head_mask, inputs_embeds=inputs_embeds, output_attentions=output_attentions, output_hidden_states=output_hidden_states, return_dict=return_dict, ) outputs = self.model( input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids, position_ids=position_ids, head_mask=head_mask, inputs_embeds=inputs_embeds, output_attentions=output_attentions, output_hidden_states=output_hidden_states, return_dict=return_dict, ) sequence_output = outputs[0] + self.norm(first_outputs[0]) logits = self.classifier(sequence_output) loss = None if labels is not None: if self.config.problem_type is None: if self.num_labels == 1: self.config.problem_type = "regression" elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int): self.config.problem_type = "single_label_classification" else: self.config.problem_type = "multi_label_classification" if self.config.problem_type == "regression": loss_fct = MSELoss() if self.num_labels == 1: loss = loss_fct(logits.squeeze(), labels.squeeze()) else: loss = loss_fct(logits, labels) elif self.config.problem_type == "single_label_classification": loss_fct = CrossEntropyLoss() loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1)) elif self.config.problem_type == "multi_label_classification": loss_fct = BCEWithLogitsLoss() loss = loss_fct(logits, labels) if not return_dict: output = (logits,) + outputs[2:] return ((loss,) + output) if loss is not None else output return SequenceClassifierOutput( loss=loss, logits=logits, hidden_states=outputs.hidden_states, attentions=outputs.attentions, )이전 계층 모델은 가중치가 학습되면 안되므로 프리징하였습니다. 이전 계층 모델의 아웃풋 히든 스테이트 벡터를 레이어 노멀라이즈하여 이전 계층 모델 정보를 얼마나 참고할지도 학습하도록 유도하였습니다. LayerNorm.weight가 학습되며 이전 계층 정보와 현재 계층 정보 간 비중을 결정합니다.
기대하고 시도해보았지만, 이전 계층 정보를 참고하지 않고 작은 카테고리에 대해서만 분류하는 모델과 Accuracy 기준으로 큰 차이를 보이진 않았습니다.
2. Accuracy Loss
다중 클래스 분류 문제에서 주로 CrossEntropyLoss를 손실함수로 사용하나, Accuracy 향상에 더욱 적합하게끔 손실함수를 조금 수정해보았습니다.
- 관련 코드 발췌
# 크로스 엔트로피 손실에 (1-정확도)를 더하여 학습 시 정확도를 높이는 방향으로 유도되도록 손실 함수를 정의 class AcurracyLoss(nn.Module): def __init__(self, epsilon=1e-7): super().__init__() self.eps = epsilon self.ce_fct = nn.CrossEntropyLoss() def forward(self, logits, labels): ce_loss = self.ce_fct(logits, labels) predictions = torch.argmax(logits, dim=-1) acc_loss = self.reverse_accuracy_score(labels, predictions) acc_loss = acc_loss.clamp(min=self.eps, max=1-self.eps) return ce_loss + acc_loss def reverse_accuracy_score(self, labels, predictions): return torch.sum(predictions != labels) / len(labels)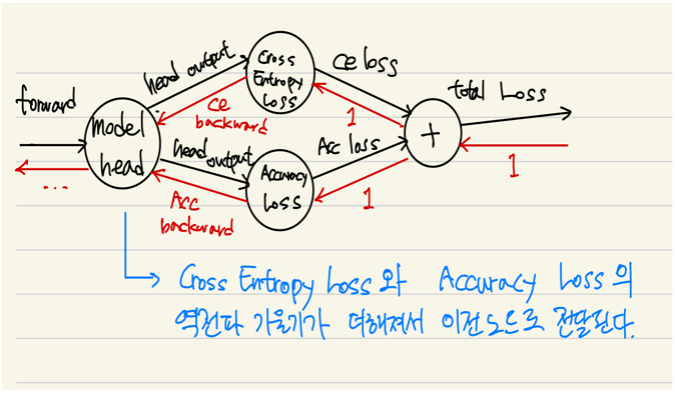
klue/roberta-base 모델과 klue/roberta-small 모델 각각에 대해 손실함수만 달리하여 학습하고 검증 결과를 비교해보았을 때 Accuracy가 소폭 상승함을 확인하였으나 검증용 데이터셋으로 예측한 결과는 CrossEntropyLoss로 학습한 결과가 조금 더 높은 Accuracy 를 보였습니다.
학습 데이터셋에 오버피팅된 것 같습니다. 하지만 CrossEntropyLoss를 손실함수로 학습시킨 모델과 약간 다른 방식으로 학습되기 때문에 모델 앙상블 시 효과가 있을 것으로 판단합니다.
+
대회 당시엔 생각하지 못했지만, Accuracy는 이산적이므로 미분이 불가능합니다. 그러므로 이론적으로는 역전파도 불가능합니다.
역전파 과정에서 오류가 발생하지 않은 이유는 파이토치 내부적으로 수치 미분을 수행하여 역전파를 수행하지 않고, 계산 그래프를 따라가며 역전파했기 때문으로 추측합니다.
torch.sum은 흘러 들어온 그레디언트를 그대로 흘려보내기 때문에, predictions과 labels가 달랐던(틀린) prediction에 대해서만 그레디언트를 흘려보냅니다.
그러므로 잘못된 예측에 기여한 파라미터들의 변화 폭을 키우는 효과만 줬을 것으로 추측합니다.
3. TAPT(Task Adapted PreTraining)
TAPT는 사전 학습된 모델을 불러와서 바로 원하는 테스크에 맞춰 파인튜닝하지 않고, 테스크 데이터셋으로 추가적인 사전 학습을 진행하는 방법을 말합니다.
Encoder 모델을 활용했기에 허깅페이스에서 제공하는 Masked Language Modeling 학습 코드를 참고하여 TAPT를 진행하였습니다.
- 관련 코드 발췌
import wandb import pickle import transformers from dataclasses import dataclass from transformers import ( AutoModelForMaskedLM, AutoTokenizer, AutoConfig, DataCollatorForLanguageModeling, TrainingArguments, Trainer ) from datasets import load_from_disk, concatenate_datasets @dataclass class PathCfg: data = "/content/drive/MyDrive/finda/ai_contest/dataset" model = "/content/drive/MyDrive/finda/ai_contest/model" @dataclass class TaptCfg: epochs = 90 batch_size = 64 grad_accumulation_steps = 4 learning_rate = 1e-5 adam_epsilon = 1e-6 adam_beta1 = 0.9 adam_beta2 = 0.98 lr_scheduler = "constant" weight_decay = 0.01 N = 4 checkpoint = f"{PathCfg.model}/TAPT/{N-1}/checkpoint-54467" tokenizer = AutoTokenizer.from_pretrained(checkpoint) model = AutoModelForMaskedLM.from_pretrained(checkpoint) print(f"\ncheckpoint: {checkpoint}\ntrial: {N}") dataset = load_from_disk(f"{PathCfg.data}/base_dataset") def tokenize_function(examples): result = tokenizer(examples["text"]) # if tokenizer.is_fast: # result["word_ids"] = [result.word_ids(i) for i in range(len(result["input_ids"]))] return result tokenized_datasets = dataset.map( tokenize_function, batched=True, remove_columns=['AI_id', 'digit_1', 'digit_2', 'digit_3', 'text'] ) data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm_probability=0.15) logging_steps = len(tokenized_datasets["train"]) // (TaptCfg.batch_size * TaptCfg.grad_accumulation_steps * 2) print(f"trial: {N}") print(f"logging_steps: {logging_steps}") training_args = TrainingArguments( output_dir=f"{PathCfg.model}/TAPT/{N}", logging_dir=f"{PathCfg.model}/TAPT/{N}/log", evaluation_strategy="steps", num_train_epochs=TaptCfg.epochs, per_device_train_batch_size=TaptCfg.batch_size, per_device_eval_batch_size=TaptCfg.batch_size, gradient_accumulation_steps=TaptCfg.grad_accumulation_steps, learning_rate=TaptCfg.learning_rate, adam_epsilon=TaptCfg.adam_epsilon, adam_beta1=TaptCfg.adam_beta1, adam_beta2=TaptCfg.adam_beta2, lr_scheduler_type=TaptCfg.lr_scheduler, weight_decay=TaptCfg.weight_decay, fp16=True, logging_steps=logging_steps, save_steps=logging_steps, eval_steps=logging_steps, report_to="wandb", run_name=f"TAPT_{N}", seed=42, ) trainer = Trainer( model=model, args=training_args, train_dataset=tokenized_datasets["train"], eval_dataset=tokenized_datasets["test"], data_collator=data_collator, tokenizer=tokenizer, ) # Train trainer.train(checkpoint) wandb.finish()
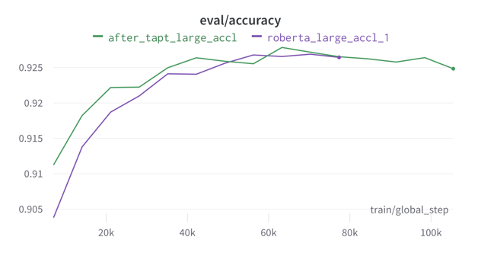
klue/roberta-large 모델에 TAPT를 진행한 다음 파인튜닝한 결과, 검증 데이터셋에서 Accuracy 점수가 소폭 상승하였습니다.
하이퍼파라미터는 참고 논문 Appendix의 Table 13: Hyperparameters for domain- and task- adaptive pretraining 표에 제시된 것 그대로 적용하였습니다.
4. Negative Sampling
Word2Vec 모델을 학습시킬 때 계산량을 줄이기 위해 Negative Sampling이라는 기법을 사용합니다. Skip-gram 방식으로 학습한다고 가정할 때, 전체 단어 집합 중에서 주변 단어들을 예측하는게 아니라 Positive sample인 실제 주변 단어가 주어지면 주변 단어라고 예측하고 Negative sample인 임의의 단어가 주어지면 해당 단어는 주변 단어가 아니라고 예측하는 이진 분류 문제로 바꾸어 모델을 학습시키는 방법이 Negative Sampling입니다.
이 방법을 변형하여 모델 사전 학습에 활용해보았습니다.
[입력 문장 / Positive label] → Positive, [입력 문장 / Negative label] → Negative 와 같이 이진 분류 문제로 바꾸어 TAPT를 적용한 klue/roberta-large 모델을 추가 학습하였습니다.
네거티브 샘플을 뽑는 과정에서 기존 모델이 자주 틀렸던 레이블들을 네거티브 레이블로 활용하여 학습을 진행한다면 더 효과가 있을 것으로 판단하였습니다. 따라서 기존에 학습시켰던 roberta-small, roberta-large 모델의 검증 결과 많이 틀린 클래스 위주로, 잘못 예측한 레이블을 negative label로 모델을 추가 학습하였습니다.
5. BiLSTM Layer 추가
앙상블에 활용되는 모델들이 서로 조금씩 다른 결과를 말할 때 일반화가 잘되는 것으로 알려져 있습니다.
모델 예측을 좀더 다양하게 유도하고자 모델과 모델 헤드(classifier) 사이에 BiLSTM Layer를 추가하였습니다.
새로운 레이어가 추가되면 모델의 표현력이 향상되어 오버피팅될 가능성이 커지지만 모델 앙상블과 드롭 아웃을 통해 완화할 수 있을 것으로 판단하였습니다.
- 관련 코드 발췌
from dataclasses import dataclass from collections import OrderedDict from typing import Any, BinaryIO, ContextManager, Dict, List, Optional, Tuple, Union import numpy as np import torch import torch.nn as nn from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss from transformers.file_utils import ModelOutput from transformers.modeling_outputs import SequenceClassifierOutput from transformers.models.roberta.modeling_roberta import RobertaClassificationHead, RobertaForSequenceClassification from transformers import RobertaPreTrainedModel, RobertaModel, AutoConfig """ 사용 예시 config = AutoConfig.from_pretrained(cfg.checkpoint, num_labels=225) model = AddLSTMForSequenceClassification(config=config, checkpoint=cfg.checkpoint) """ class RobertaClassificationHeadForLSTM(nn.Module): """Head for sentence-level classification tasks.""" def __init__(self, config): super().__init__() self.dense = nn.Linear(config.hidden_size, config.hidden_size) classifier_dropout = ( config.classifier_dropout if config.classifier_dropout is not None else config.hidden_dropout_prob ) self.dropout = nn.Dropout(0.2) self.out_proj = nn.Linear(config.hidden_size, config.num_labels) def forward(self, features, **kwargs): x = self.dense(features) x = torch.tanh(x) x = self.dropout(x) x = self.out_proj(x) return x class AddLSTMForSequenceClassification(RobertaForSequenceClassification): def __init__(self, config, checkpoint): super().__init__(config) self.num_labels = config.num_labels self.config = config self.model = RobertaModel.from_pretrained( checkpoint, config=config, add_pooling_layer=False ) self.norm = nn.LayerNorm(config.hidden_size) self.dropout = nn.Dropout(0.2) self.BiLSTM = nn.LSTM( config.hidden_size, config.hidden_size, # LSTM 층을 더 쌓고 싶다면 num_layers 수정 num_layers=1, batch_first=True, dropout=0.2, bidirectional=True ) self.classifier = RobertaClassificationHeadForLSTM(config) # self.init_weights() def forward( self, input_ids=None, attention_mask=None, token_type_ids=None, position_ids=None, head_mask=None, inputs_embeds=None, labels=None, output_attentions=None, output_hidden_states=None, return_dict=None, ): r""" labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size,)`, `optional`): Labels for computing the sequence classification/regression loss. Indices should be in :obj:`[0, ..., config.num_labels - 1]`. If :obj:`config.num_labels == 1` a regression loss is computed (Mean-Square loss), If :obj:`config.num_labels > 1` a classification loss is computed (Cross-Entropy). """ return_dict = return_dict if return_dict is not None else self.config.use_return_dict outputs = self.model( input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids, position_ids=position_ids, head_mask=head_mask, inputs_embeds=inputs_embeds, output_attentions=output_attentions, output_hidden_states=output_hidden_states, return_dict=return_dict, ) sequence_output = outputs[0] # 모델 아웃풋 sequence_output = self.dropout(sequence_output) lstm_outputs = self.BiLSTM(sequence_output)[0] # LSTM 아웃풋 중 히든 스테이트 벡터를 추출 lstm_output = lstm_outputs[:, -1, :] # 마지막 시점의 히든 스테이트 벡터 추출 # 정방향으로 계산을 진행하며 나온 벡터와 역방향으로 진행하며 나온 벡터를 나눈 다음 합했습니다. lstm_output = lstm_output[:, :self.config.hidden_size] + lstm_output[:, self.config.hidden_size:] # Residual Connection # LSTM 히든 스테이트 벡터와 RoBERTa 히든 스테이트 벡터(각 시퀀스 벡터를 모두 합한 것([CLS] X))의 예측 시 비중을 # LayerNorm을 통해 학습되도록 유도 output = self.norm(torch.sum(sequence_output, dim=-2)) + self.norm(self.dropout(lstm_output)) logits = self.classifier(output) loss = None if labels is not None: if self.config.problem_type is None: if self.num_labels == 1: self.config.problem_type = "regression" elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int): self.config.problem_type = "single_label_classification" else: self.config.problem_type = "multi_label_classification" if self.config.problem_type == "regression": loss_fct = MSELoss() if self.num_labels == 1: loss = loss_fct(logits.squeeze(), labels.squeeze()) else: loss = loss_fct(logits, labels) elif self.config.problem_type == "single_label_classification": loss_fct = CrossEntropyLoss() loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1)) elif self.config.problem_type == "multi_label_classification": loss_fct = BCEWithLogitsLoss() loss = loss_fct(logits, labels) if not return_dict: output = (logits,) + outputs[2:] return ((loss,) + output) if loss is not None else output return SequenceClassifierOutput( loss=loss, logits=logits, hidden_states=outputs.hidden_states, attentions=outputs.attentions, )
6. 앙상블
모델 아키텍처는 RoBERTa 하나만 사용했지만, 다양한 방법들을 적용하거나 large, base, small 같이 모델 사이즈를 달리하여 모델 별로 조금씩 차이를 두고 학습하였습니다. 이를 통해 모델 별로 조금씩 다른 결과를 유도하고 그 결과를 앙상블하여 오버피팅을 완화하였습니다.
최종적으로 소분류 예측 모델 12개를 소프트 보팅 방식으로 앙상블하여 소분류 계층을 예측하였고, 소분류 예측 모델의 중분류 예측 결과 12개와 중분류 예측 모델 3개의 결과를 하드 보팅 방식으로 앙상블하여 중분류 계층을 예측하였습니다. 대분류는 소분류 예측 모델의 소프트 보팅 결과를 토대로 예측하였습니다.
이렇듯 짧은 시간동안 몰입하여 다양한 시도를 하였고, 그 결과 대회 순위권에 오를 수 있었습니다. 대회 문제를 풀기 위해 코랩 환경에서 작성한 코드는 이곳에서 확인할 수 있습니다.
마지막으로
궁금한 부분을 이해하기 위해 조금 더 구체적으로 공부하려고 했던 점이 좋은 결과를 이끈 것 같습니다.
그렇지 않았다면 역전파 과정이 코드 상으로 어떻게 구현되었는지, 라이브러리를 통해 쉽게 불러와서 쓰는 모델의 코드가 어떻게 구현되었는지 같은 부분은 몰랐을테고 다양한 방법들을 적용해보기에 한계가 있었을 것입니다.
부족한 점은 많지만, 텍스트 분류 문제를 풀기 위해 효과적인 방법들을 고민해보고 적용해보며 성장할 수 있었던 좋은 경험이었다고 생각합니다.
이러한 대회를 제공해주신 통계청에 감사합니다.
